Generative adversarial networks (GANs) are a type of deep learning model that have been gaining popularity in the field of image processing. GANs are used to generate realistic images that are similar to a given set of training images. In this blog, we will discuss the basics of GANs and how they can be used for image processing tasks with the help of an example.
What are GANs?
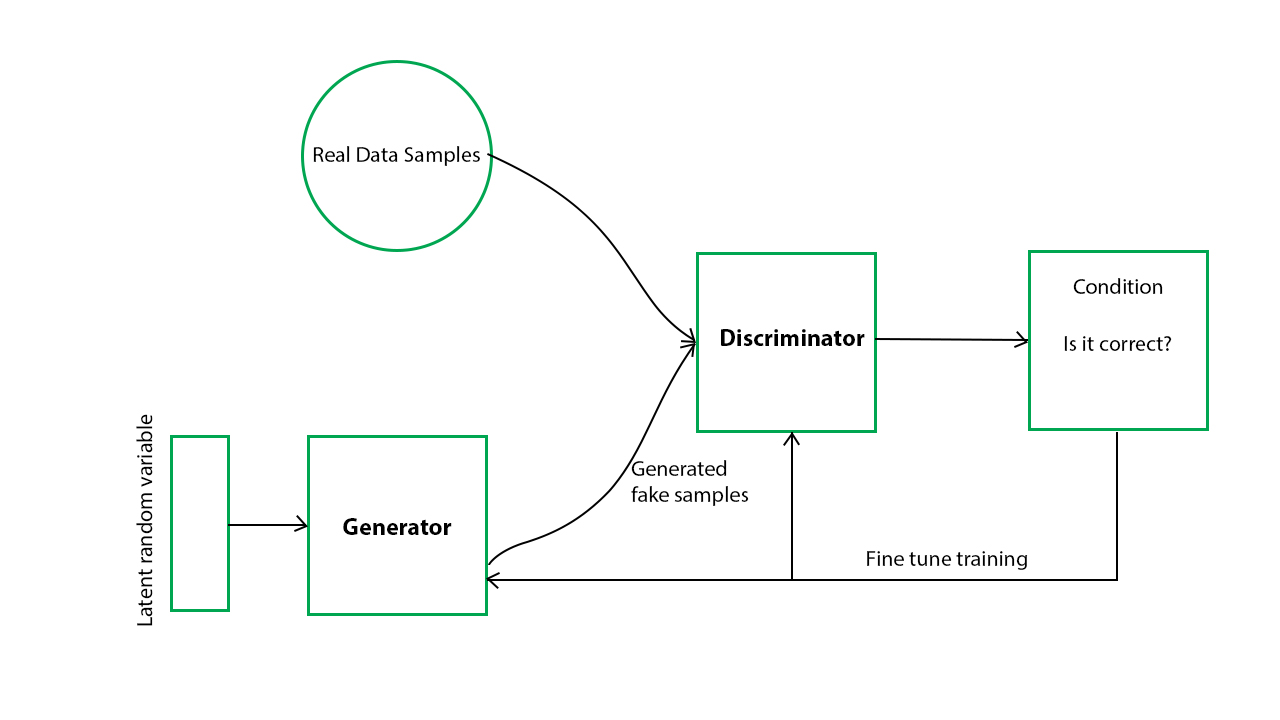
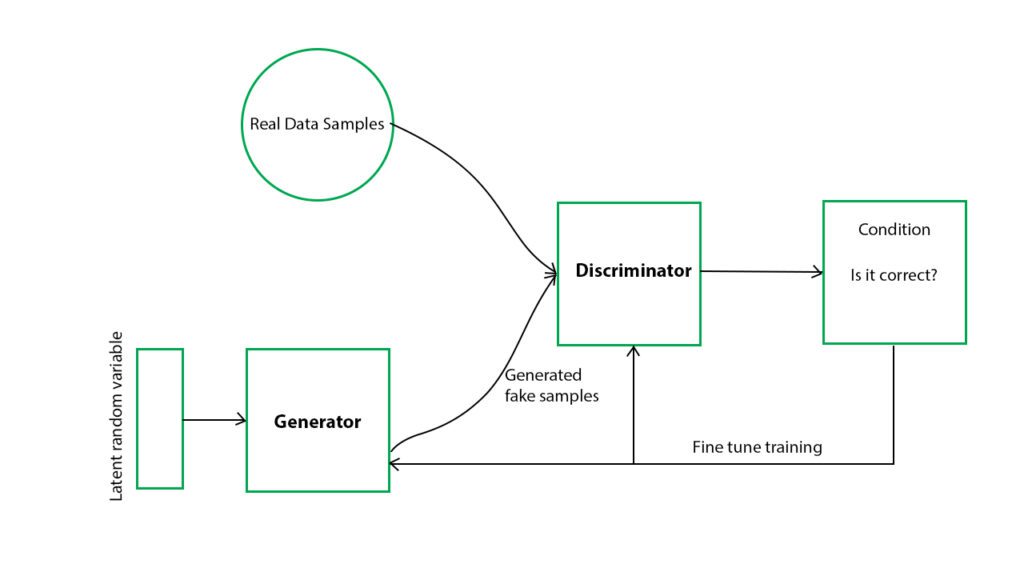
A GAN consists of two neural networks, a generator and a discriminator, that are trained together in an adversarial manner. The generator generates images, while the discriminator evaluates whether the generated images are real or fake. The goal of the generator is to generate images that are indistinguishable from real images, while the goal of the discriminator is to correctly identify whether an image is real or fake.
How do GANs work?
At the beginning of the training process, the generator generates random noise, which is then fed to the discriminator along with a set of real images. The discriminator evaluates each image and provides feedback to the generator on how to improve the generated images. The generator then uses this feedback to adjust its parameters and generate more realistic images. This process is repeated until the generator can produce images that are indistinguishable from real images.
Example of GANs for Image Processing
One of the most common applications of GANs in image processing is image super-resolution. Image super-resolution is the process of increasing the resolution of a low-resolution image to a higher resolution. This is useful in applications where high-resolution images are required, such as medical imaging, satellite imaging, and surveillance.
Let’s consider an example of image super-resolution using GANs. Suppose we have a dataset of low-resolution images of faces. Our goal is to generate high-resolution images of faces from these low-resolution images using GANs.
First, we train the discriminator on a set of high-resolution images of faces and a set of low-resolution images generated from the high-resolution images. The discriminator learns to distinguish between high-resolution and low-resolution images. Next, we train the generator to generate high-resolution images from the low-resolution images using feedback from the discriminator. The generator uses a combination of upsampling and convolutional layers to increase the resolution of the low-resolution images.
Once the generator is trained, we can use it to generate high-resolution images of faces from low-resolution images. The generated images will be visually pleasing and will contain details that were not present in the original low-resolution images.
Conclusion
GANs are a powerful tool for image processing tasks such as image super-resolution, style transfer, and image inpainting. With their ability to generate realistic images, GANs are poised to revolutionize the field of image processing. However, GANs can be challenging to train and may require large amounts of data and computational resources. Nevertheless, ongoing research in this area is improving the performance and efficiency of GANs, making them more accessible for practical applications.



{kind=link}